配置环境
|
1 2 3 |
pip install selenium pip install redis pip install PyMySQL |
然后在import MySQLdb之前加上
|
1 2 |
import pymysql pymysql.install_as_MySQLdb() |
安装scrapyd
安装后会出现在python的bin目录下。
安装命令:pip install scrapyd
验证scrapyd安装
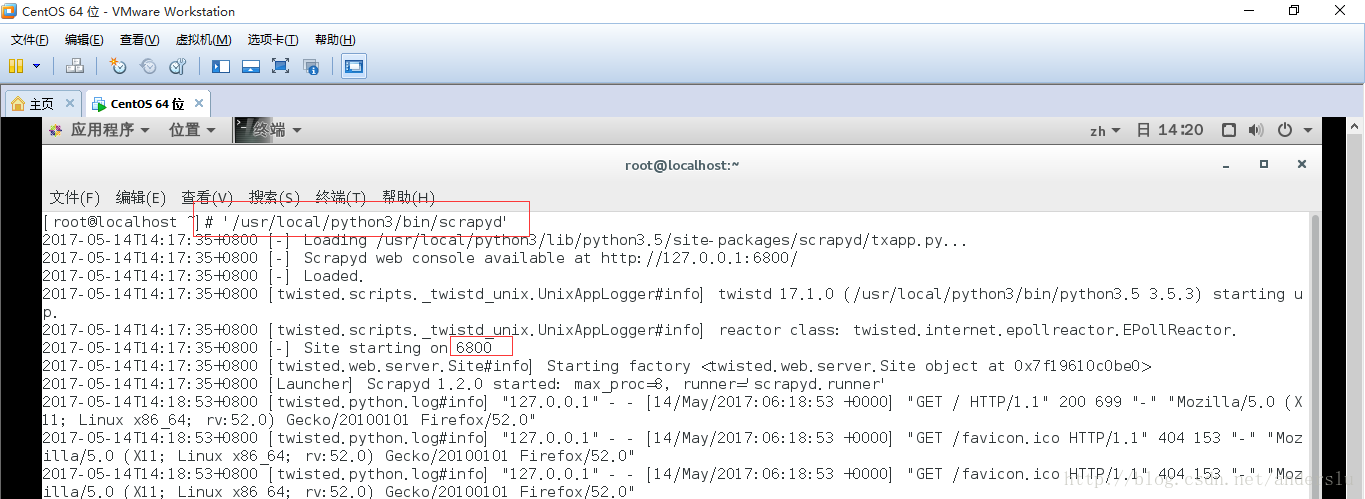
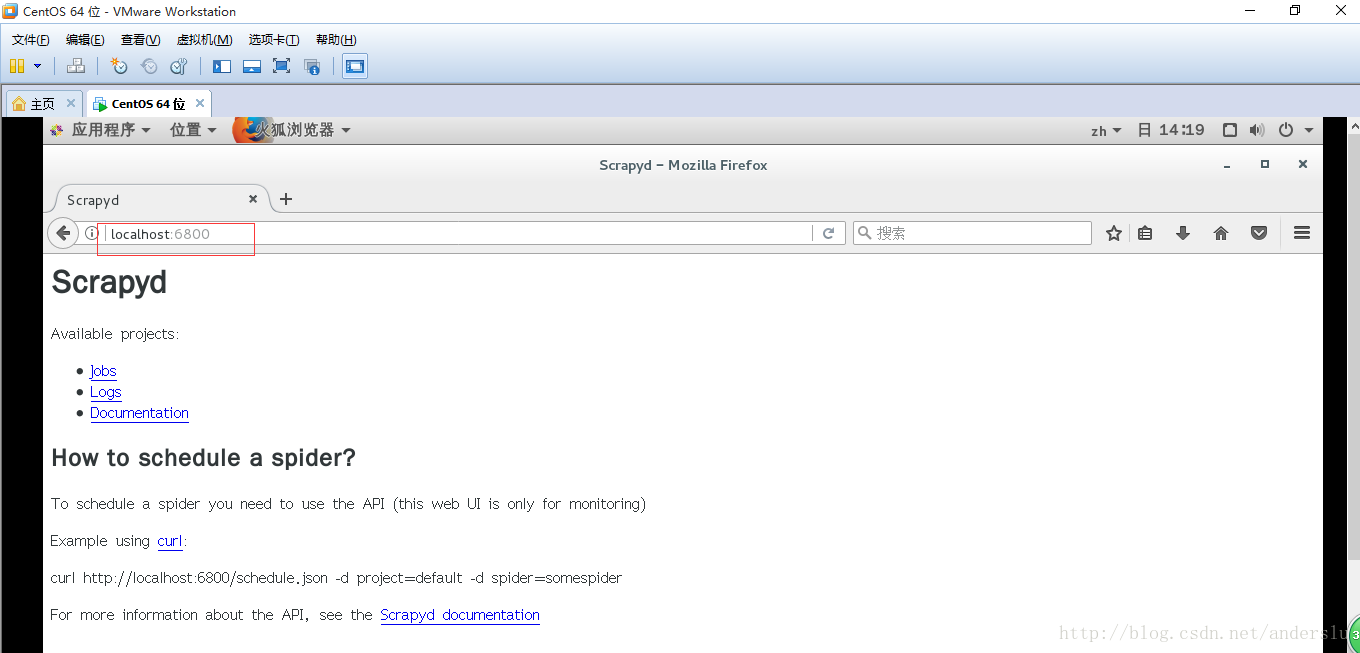
在命令行执行执行scrapyd命令即可启动scrapyd,执行完命令后如下图
安装上传工具(scrapyd-client)
Scrapyd-client是一个专门用来发布scrapy爬虫的工具,安装后会出现在python的bin目录下。
安装命令:pip install scrapyd-client
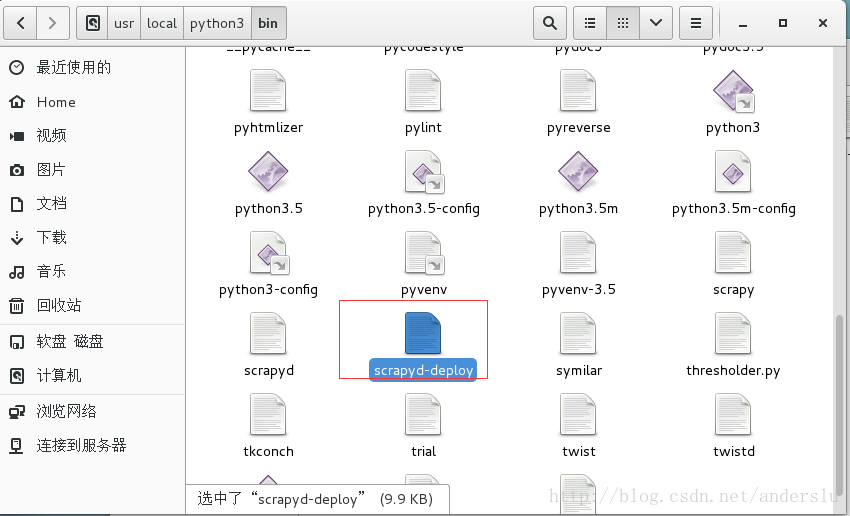
发布-(拷贝scrapyd-deploy到爬虫目录下)
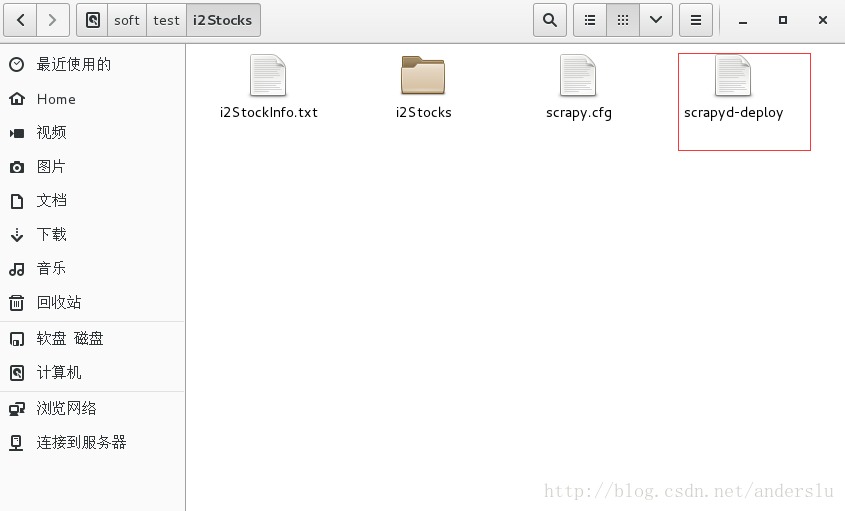
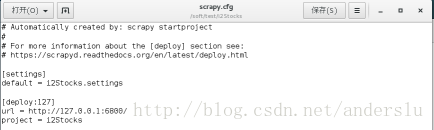
发布-(修改爬虫的scapy.cfg文件)
1、去掉url前的注释符号,这里url就是你的scrapyd服务器的网址;
2、deploy:127表示把爬虫发布到名为127的爬虫服务器上,deploy:后的名字可以自己定义;
3、default=i2Stocks .settings 建议用工程名字。
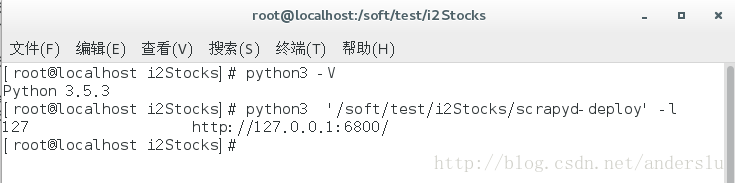
验证配置:执行如下命令python3 scrapyd-deploy -l
预期结果如下:
发布-(上传scrapy到scrapyd)
|
1 |
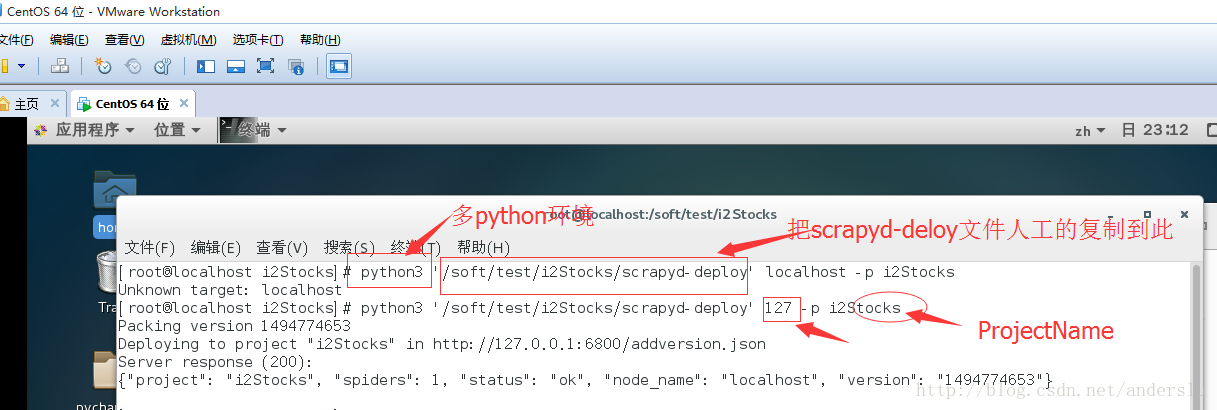
上传命令:python3 <span class="hljs-string">'/soft/test/i2Stocks/scrapyd-deploy'</span> <span class="hljs-number">127</span> <span class="hljs-attribute">-p</span> i2Stocks |
- 1
7、使用linux自带的调度工具执行刚刚发布的爬虫
确认当前的linux系统有这个工具curl
curl的介绍请参见:百度百科curl介绍。

|
1 |
发布job命令:curl http://localhost:<span class="hljs-number">6800</span>/schedule.json <span class="hljs-operator">-d</span> project=i2Stocks <span class="hljs-operator">-d</span> spider=stocks |
- 1
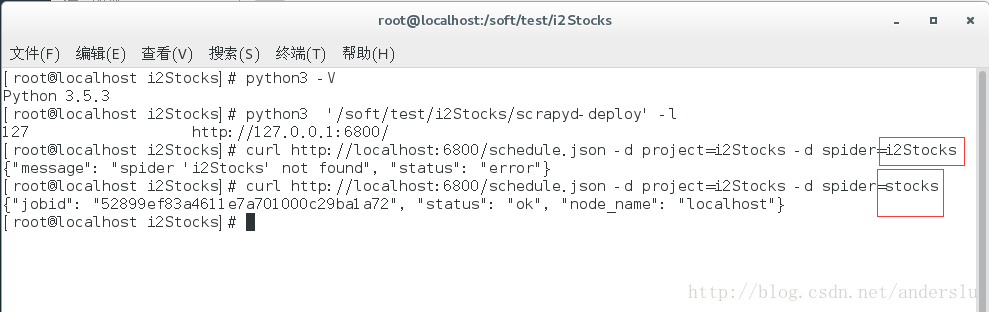
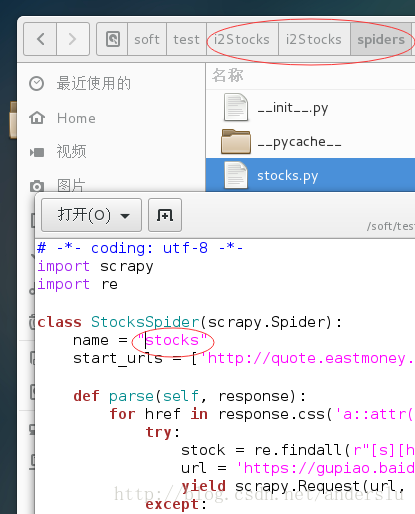
我遇到的问题是spider与工程名称不一致,查看spider的名称,可以通过如下截图获取:
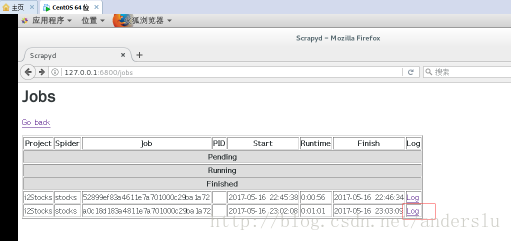
查看job执行情况及运行日志方法如下:

Comments | NOTHING